
Socialgist collects content from all over the web. Some of this content comes via partnerships with various providers. But when you visit as many corners of the web as we do, you may find that some content can only be collected by old fashioned web crawling.
In my 12 years working at Socialgist, the landscape of the web has changed. In the past, web scraping consisted of mainly static pages where content could be found directly in the HTML, but times have changed. These days, pages feature much more dynamic content. Between single page applications, JSON data, API endpoints, and many other technologies, collecting content on the web is as challenging as ever.
With the changing web, new crawling solutions are required to keep up. Our legacy crawling solution is very capable but does not always handle many of these new challenges gracefully. We also wanted to build something which could generate the statistics to allow our operations team and product managers to build highly detailed real time dashboards about all the sources we crawl. Finally, we needed something which could easily be containerized and launched to the scale we need.
We looked at many solutions but none of those were robust enough to handle the diverse types of crawling which we needed to do. We ultimately built a custom crawler using NodeJS which took the best from many open source libraries. We decided to call this crawler the Pauk (паук) crawler. Pauk being the Serbian word for spider, as an homage to the many Serbian developers on the crawling teams.
The Pauk crawler was designed to be easily configurable to handle any content type. The Pauk crawler handles the low level interactions such as setting headers, proxies, and making the fetch. The crawler framework can then be extended by a developer and apply rules specific to the content type being crawled. The crawler can be further extended to configured with logic for a specific site or group of sites.
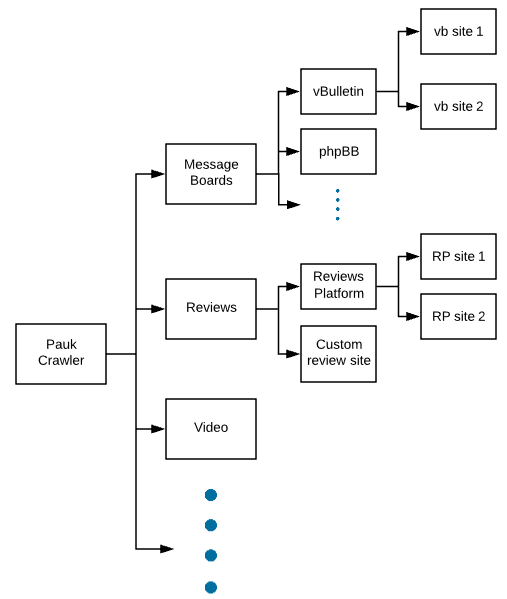
Some of the key libraries we utilized for the Pauk project…
- cheerio – Used by the crawler to write selectors to easily parse both HTML and JSON
- puppeteer – Useful library for crawling complex websites which require rendering the page
- node-rdkafka – Kafka is a critical component of our infrastructure for moving high volumes of data
- Winston – logging and reporting
The Pauk project is still in its infancy and continues to be enhanced, but has started being used for crawling some new data sources. Over time, the team expects to complete the massive task of slowly transitioning all our crawlers over to this new framework.

